Paperboy
There are 100+ AI research papers posted on arXiv every day.
I need to keep up. So do you. So does everyone building AI products. But I can't keep up. So I don't learn.
This is a serious problem for me as someone building AI products day in, day out.
The existing solutions are all apps. Semantic Scholar. Connected Papers. ResearchRabbit. Paper Digest. Each one with its own database, its own interface, its own subscription.
None of them know what I'm working on.
So I built something different.
Introducing Paperboy [ paperboy.sh ]
Paperboy is an MCP server for AI research discovery for practitioners (not academics).
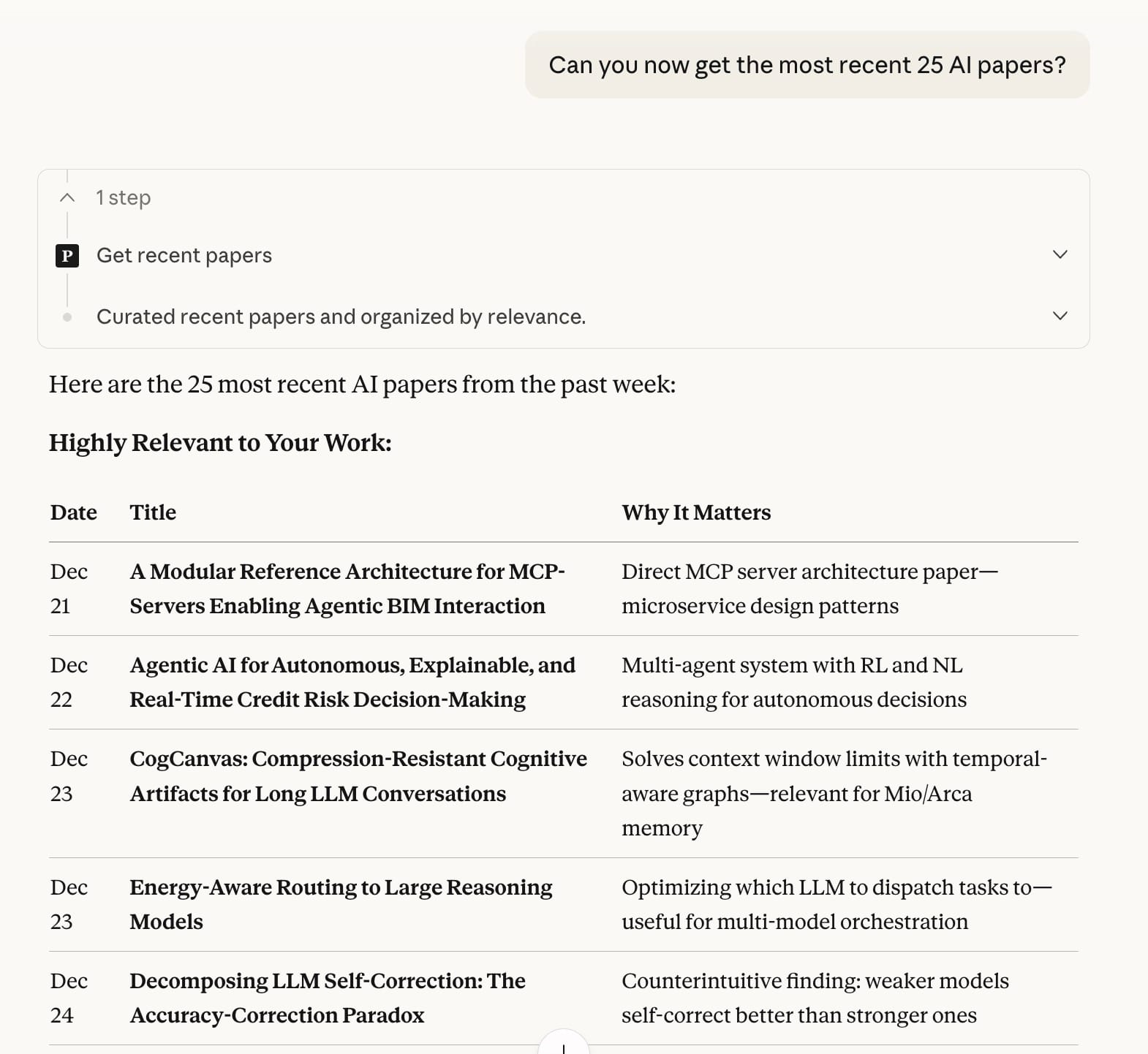
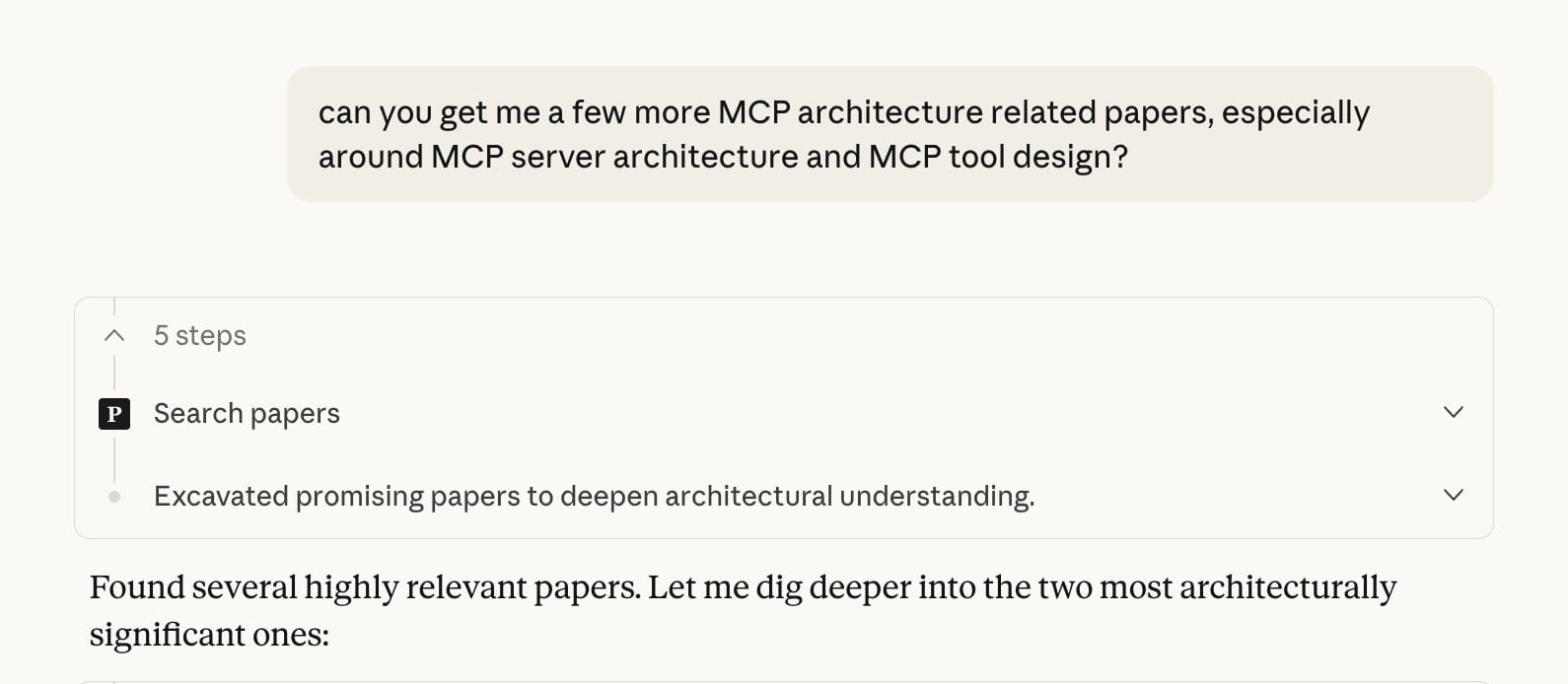
You connect it to Claude/Claude Code or ChatGPT and ask it questions like "what papers came out this week about memory in agents" or "show me anything related to retrieval."
See my usage screenshots below to see how it works.
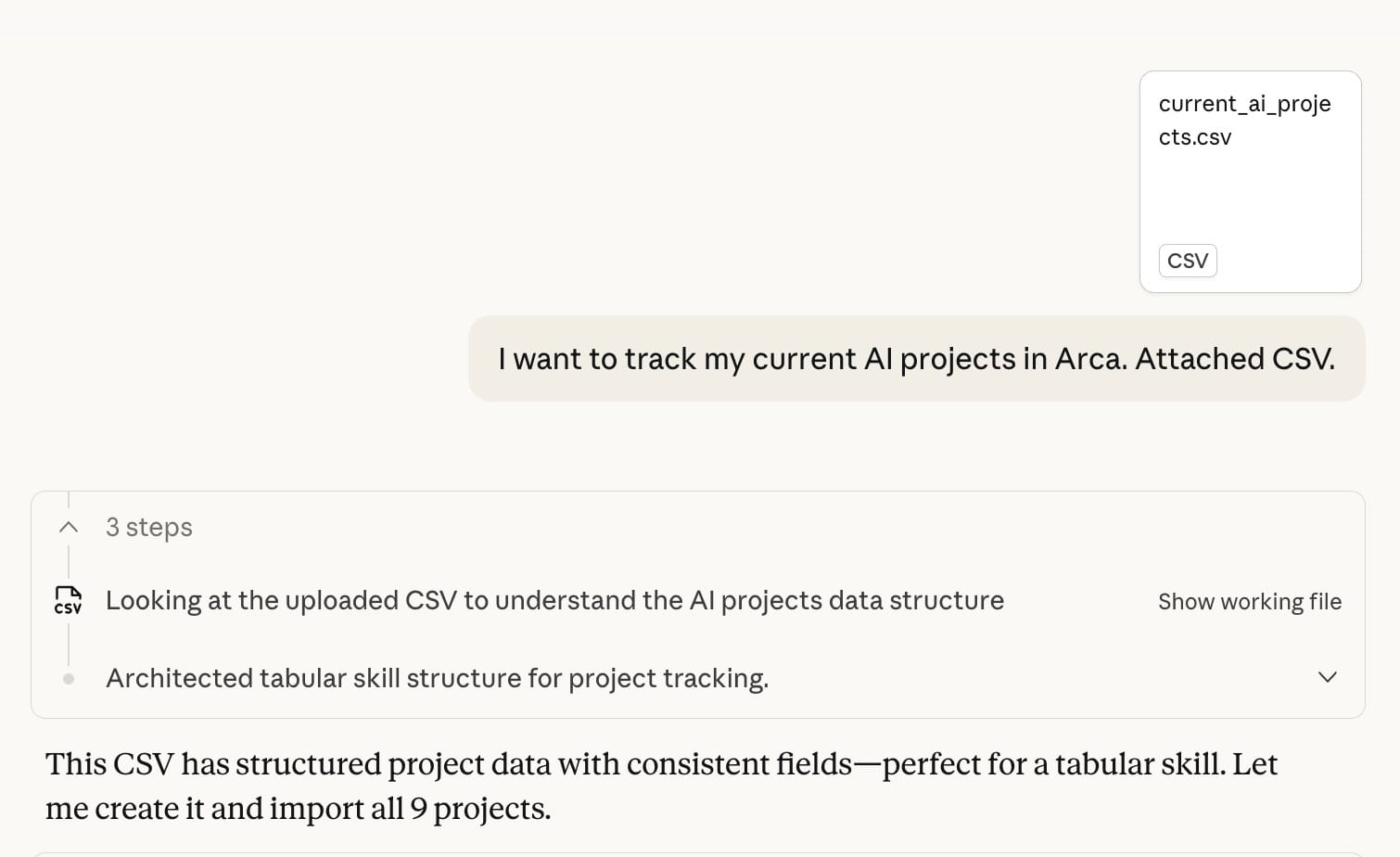
The cool part happens when you combine it with Arca [ arca.build ].
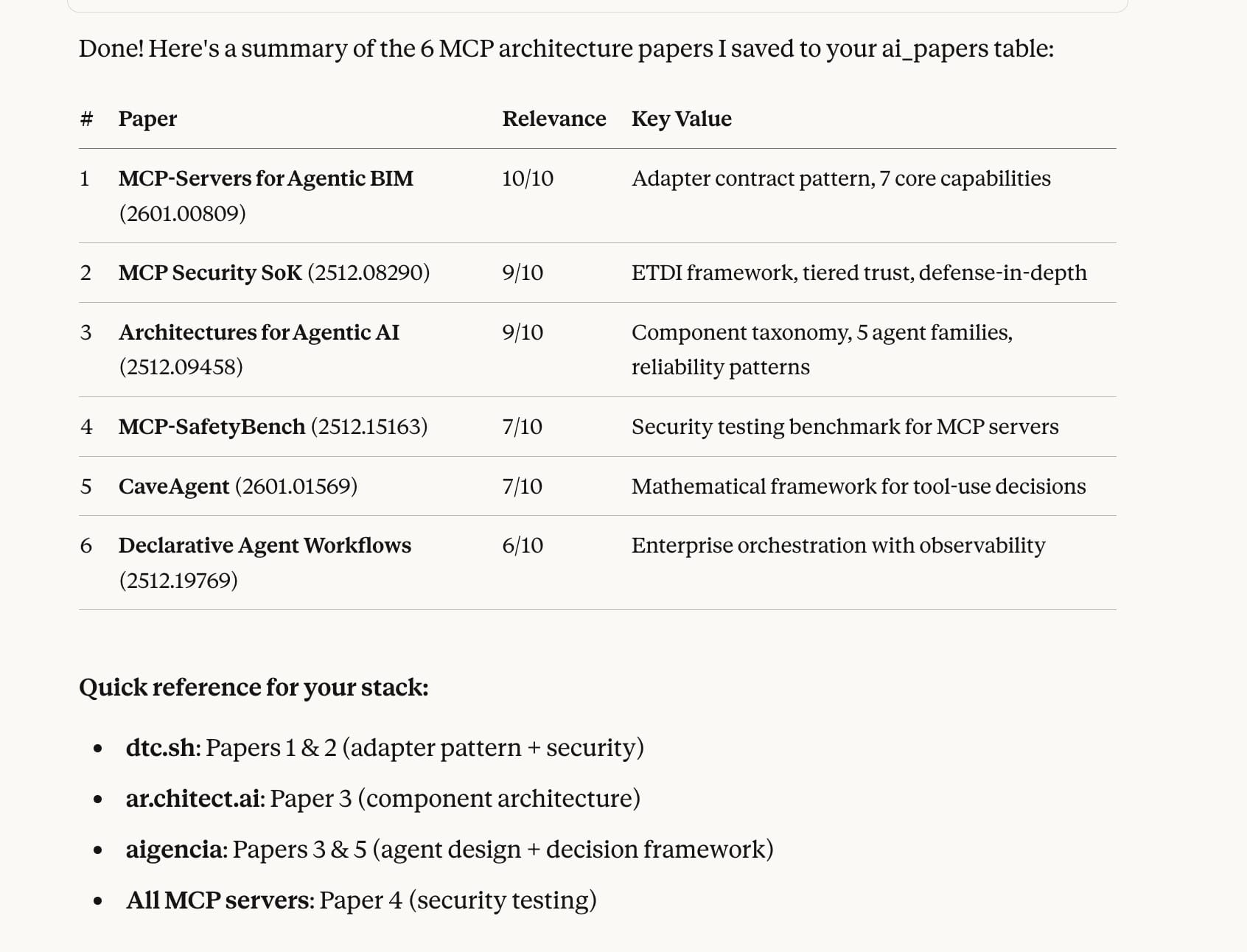
If you store your current AI projects in Arca, Paperboy can match incoming papers against your actual work. Every day it checks new papers, scores them for relevance to what you're building, and sends you only what matters.
Papers that are relevant to you, delivered to your inbox with recommendations on how to apply them.
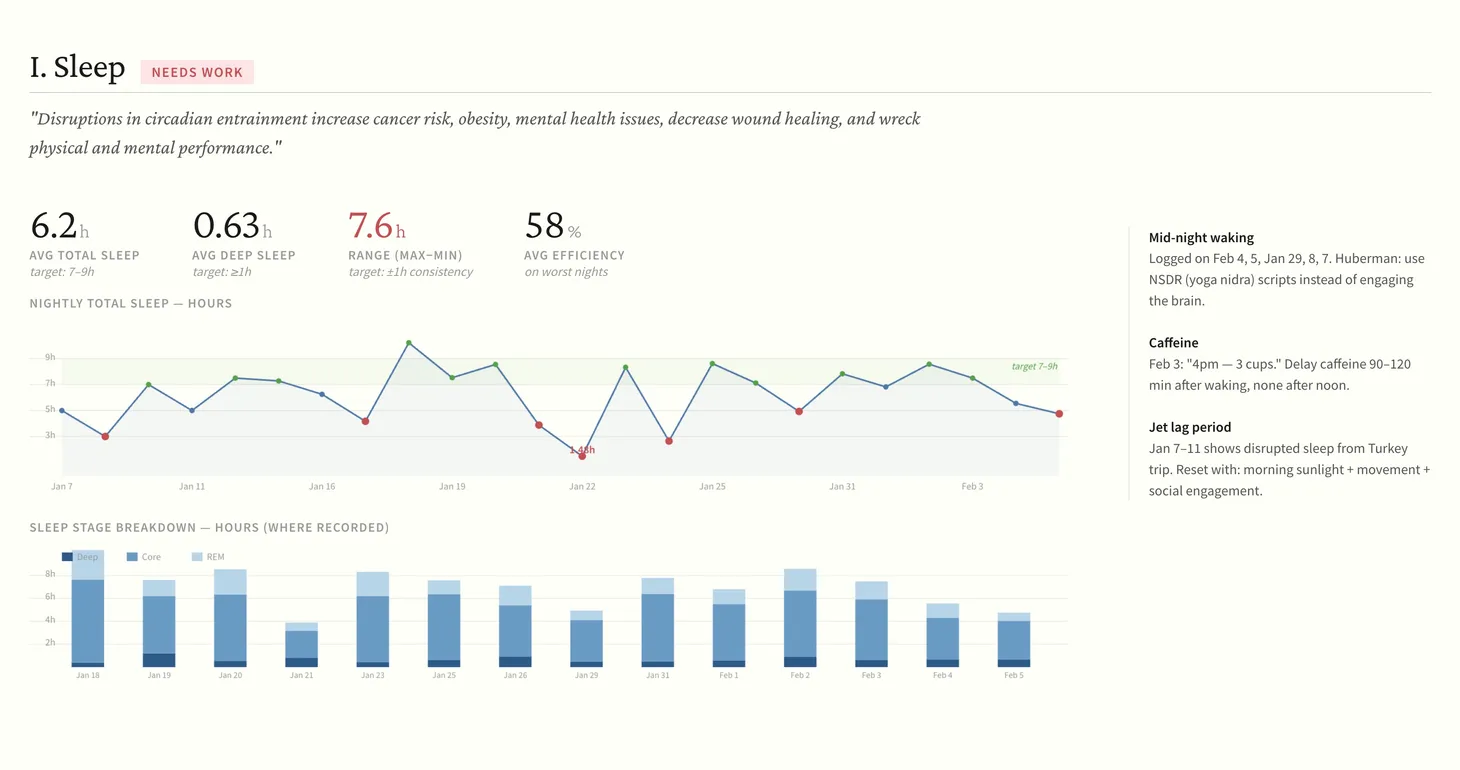
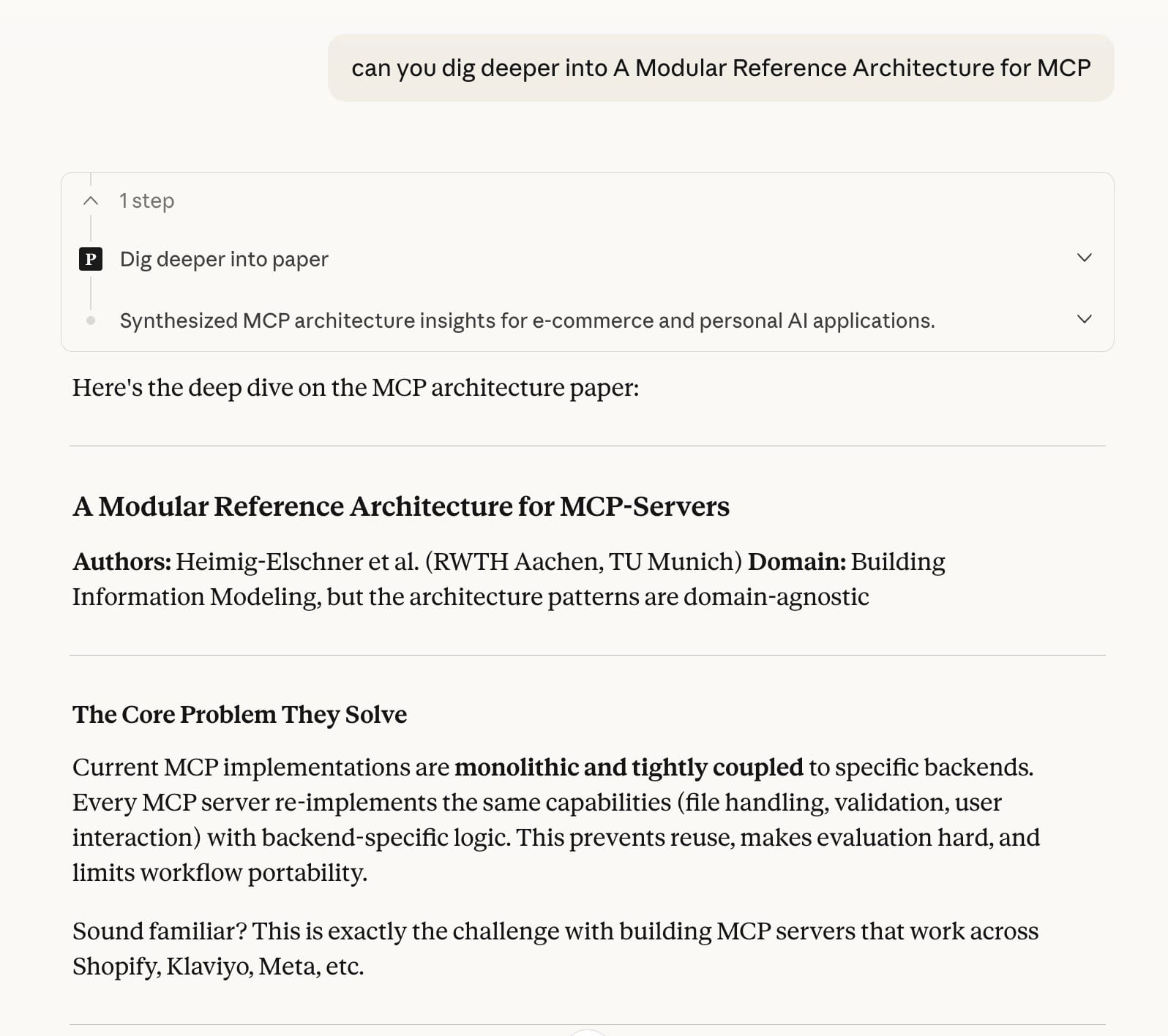
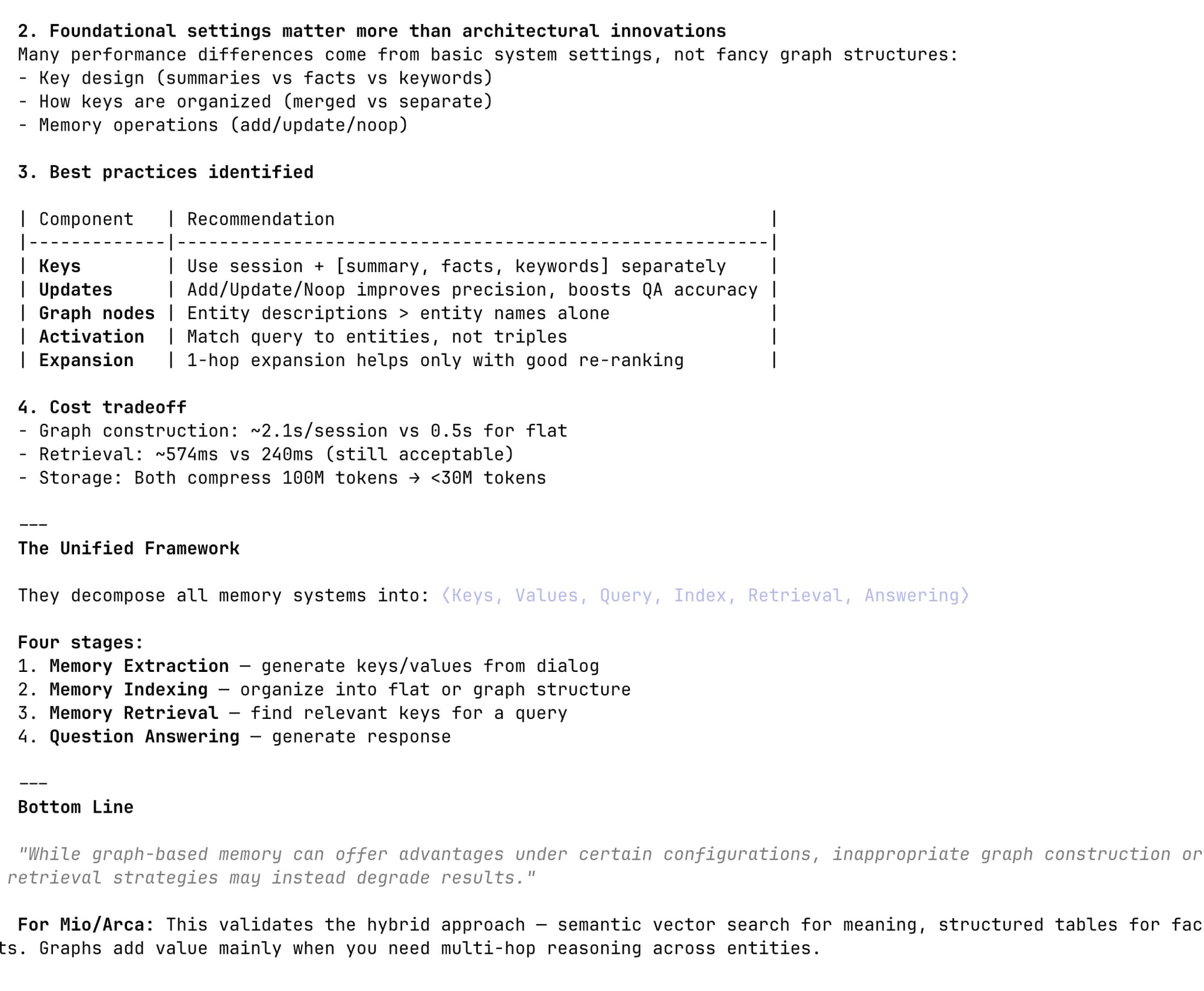
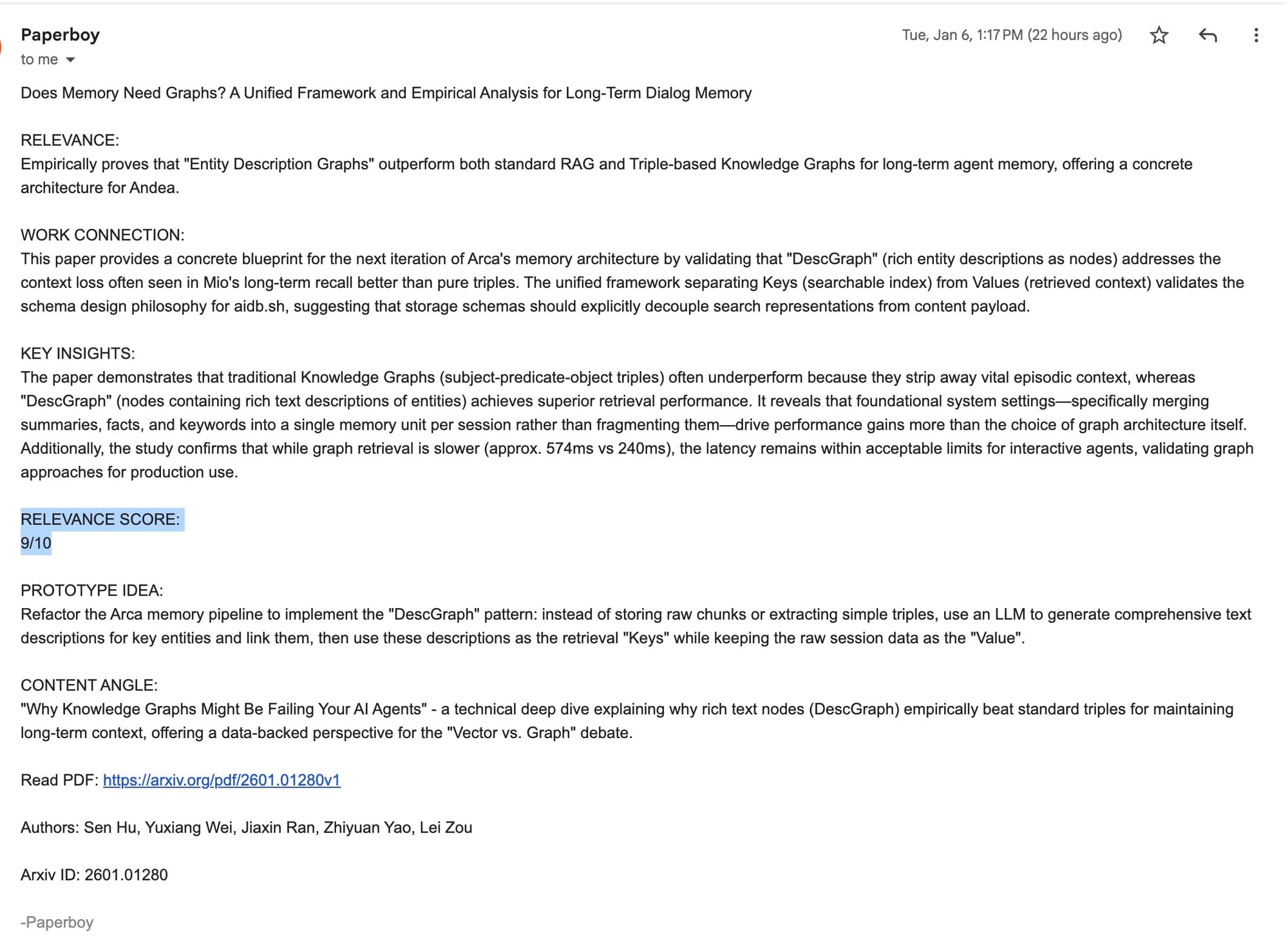
See that Claude Code example below that is super relevant to me. Arca uses vector memory for text-heavy data using LanceDB and parquet files for structured data using DuckDB. Both stored as data files in AWS S3.
I have been contemplating adding graph memory to it but haven't done it yet. This paper about graph memory was really helpful to me thinking through it.
Paperboy emailed that paper to me out of thin air because it knows how relevant it is to me.
Why this matters for the apps-no-more thesis
In November I wrote that apps will die and be replaced by personal AI plus skills plus data you own.
Paperboy is another proof point.
It's not a traditional app. It's an MCP server. You access it through whatever AI interface you already use. The data about your projects lives in Arca, which you control. The matching happens through an AI agent that reasons about relevance.
The pattern keeps repeating:
- The AI interface replaces the app UI
- The reasoning layer replaces the app logic
- Arca replaces the app database
Research discovery is just the latest category to fall.
The ecosystem forming
What's interesting to me is that Paperboy uses Arca as its data layer. I didn't have to build a new database for user projects. The infrastructure already existed.
This is what I hoped would happen when I built Arca. Products that build on top of it. Shared context across tools. Data that stays with the user.
Try it
Connect the Paperboy MCP server to Claude/Claude Code or ChatGPT: mcp.paperboy.sh
If you want the full personalized pipeline, store your projects in Arca and import the n8n template. Takes about 5 minutes.
DM me on LinkedIn and let me know if you run into any issues setting it up.
Bora
-





Maker's Wave Newsletter
Join the newsletter to receive the latest updates in your inbox.